
Consistent Hashing: Simplifying Data Distribution in Distributed Systems
EP08 | System Design | HLD Series | #04

If you've ever wondered how big tech manages to handle millions of users without crashing, a huge part of the answer lies in Consistent Hashing. From social media giants to massive online retailers, consistent hashing is a go-to strategy that keeps distributed systems scalable, reliable, and fast.
In this article, we'll break down the essentials of hashing, consistent hashing, why they’re critical, and how to implement them practically. We'll cover everything from basic concepts to real-world examples, plus best practices and tips to make your implementation as smooth as possible.
First, What is Hashing?
Hashing is a technique that takes an input (like a user ID or a URL) and converts it into a fixed-size string of characters, usually through a hash function. This hashed value determines where the data will be stored or which server will process a request.
For example, if you’re hashing a user ID of 1234, the hash function might convert it into a string like d87f7e0c based on its algorithm. If you have multiple servers, you can map this hash value to one of them based on a simple formula, such as:
Server=hash(key)%Number of Servers\text{Server} = \text{hash(key)} \% \text{Number of Servers}Server=hash(key)%Number of Servers
This is great for storing data across multiple nodes initially, but hashing on its own isn’t perfect for a dynamic system where nodes (servers) are added or removed frequently.
Why Plain Hashing Isn’t Enough
In a growing system, nodes will likely need to be added or removed regularly. With plain hashing, every time this happens, all the data needs to be reassigned to different nodes. For example, if you go from 4 to 5 servers, the modulo operation changes, which means that each data key will hash to a different server. This causes:
Heavy Data Migration: Most data points will need to be moved, which is a huge computational cost and can cause downtime.
Disruption in Load Distribution: The system needs to remap all data, creating a short-term overload on some nodes and an underutilization of others.
Reduced Fault Tolerance: When nodes are removed (e.g., during maintenance), significant rehashing can cause some data to become unavailable temporarily.
These challenges highlight the need for a more dynamic approach to data distribution. And that’s where Consistent Hashing comes in.
What is Consistent Hashing?
Consistent Hashing is a technique that minimizes data movement when nodes are added or removed. It was designed to overcome the limitations of plain hashing by ensuring that only a small portion of the data needs to be remapped when changes occur in the system.
How Consistent Hashing Works:
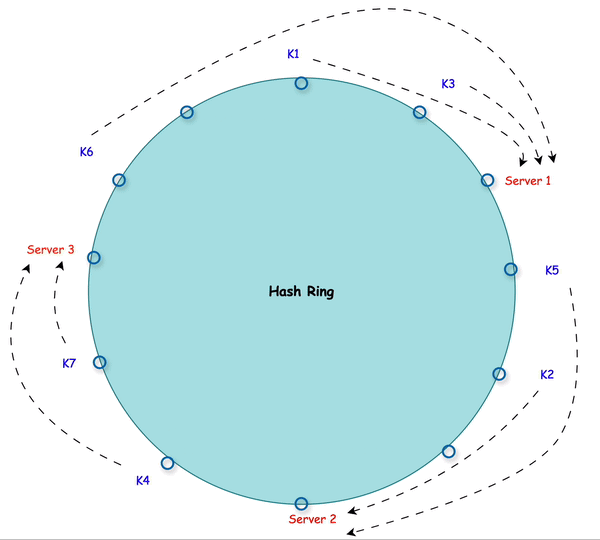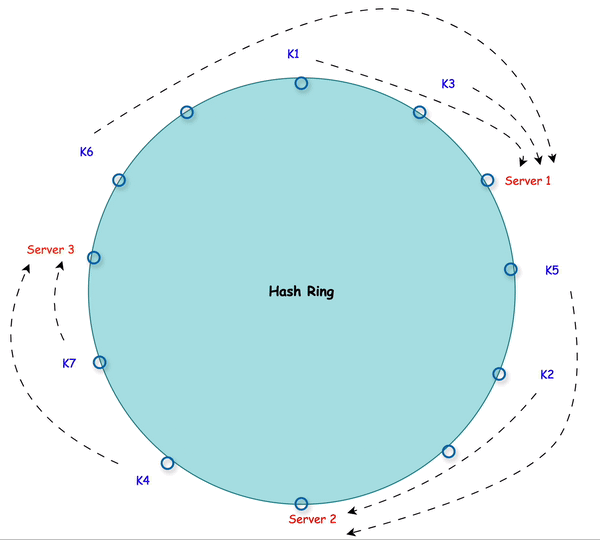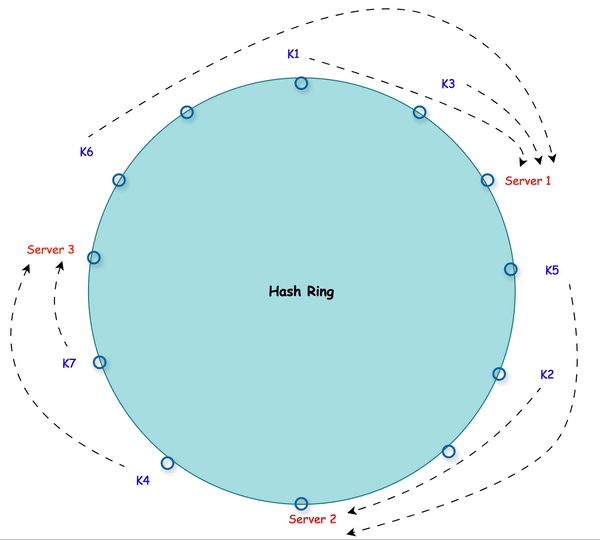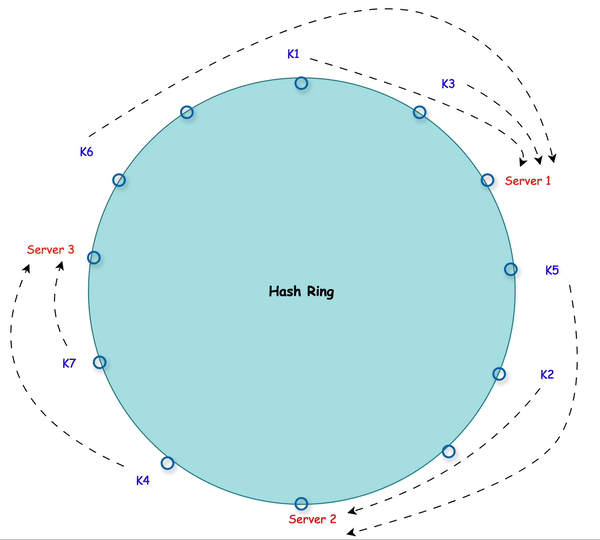
Create a Hash Ring: Instead of using a modulo operation, consistent hashing maps both nodes and data keys onto a circular “hash ring.” Each node is assigned a position on this ring using a hash function.
Data Assignment: Each data key is also hashed to a position on the ring. The data is assigned to the closest node in a clockwise direction.
Handling Changes: When nodes are added or removed, only the data immediately surrounding the affected node needs to be reassigned. This keeps the disruption minimal, unlike traditional hashing, which would affect all nodes.
Why Use Consistent Hashing?
Consistent hashing solves two critical issues in distributed systems:
Smooth Scaling: You can add or remove nodes without reshuffling everything.
Balanced Load: With the addition of virtual nodes (more on this soon), data is distributed evenly, even if nodes have varying capacities.
Real-World Examples
1. Distributed Caching (e.g., Memcached, Redis Cluster)
Large websites cache frequently-accessed data to speed up response times. Consistent hashing helps these cache clusters add or remove servers without “cache misses” that happen when data needs to be reassigned to new locations.
2. Load Balancers in CDNs
CDNs use consistent hashing to route user requests to the nearest or least-loaded server. This minimizes data reassignment when servers go offline or scale up.
3. Distributed Databases (e.g., Cassandra, DynamoDB)
NoSQL databases use consistent hashing to shard data across multiple nodes, making sure data remains available and balanced across servers, even when nodes change.
Step-by-Step Guide to Implementing Consistent Hashing
Let’s walk through a simple, user-friendly way to set up consistent hashing for your own application.
Step 1: Create a Hash Ring
The hash ring maps nodes in a circular manner, from 0 to a maximum integer (often 2322^{32}232 for convenience). Every node (e.g., a server) is hashed onto this ring using a consistent hash function like MD5 or SHA-256.
Step 2: Assign Data to Nodes
Every data key (like a user ID or session ID) is hashed to a position on this ring. The data is assigned to the first node it encounters clockwise from its hash position. This node becomes responsible for storing or processing this data.
Step 3: Handling Node Additions and Removals
Adding a Node: Place the new node on the hash ring by hashing its identifier. It will now handle data between its position and the next node clockwise, requiring only a small data migration.
Removing a Node: If a node fails or is removed, its data is simply taken over by the next node clockwise, making data migration minimal and keeping the system stable.
Best Practices for Implementing Consistent Hashing
To make the most of consistent hashing, here are some best practices to follow:
Use Virtual Nodes (VNodes) for Load Balancing
Why? Physical nodes may have different capacities or workloads. By adding multiple “virtual nodes” for each physical node on the hash ring, you ensure a more even data distribution.
How? Each physical server is mapped to several points on the ring (virtual nodes), balancing out the load even if some servers are more powerful.
Choose a Stable Hash Function
Use a reliable, stable hash function like SHA-256 or MD5 for consistent results. A good hash function will minimize collisions and ensure nodes are evenly distributed across the ring.
Plan for Fault Tolerance
Replication: For critical systems, consider replicating data across multiple nodes to prevent data loss if a node fails.
Backups: Regularly back up your data to guard against unexpected issues.
Monitor Load Balancing
Use monitoring tools to watch for any imbalances and adjust the number of virtual nodes or nodes themselves if one server is handling too much or too little data.
Example of Consistent Hashing in Action
Let’s look at an example of consistent hashing in a simple caching system:
Step 1: You have four nodes in your system: Node A, Node B, Node C, and Node D. Each node is placed on the hash ring.
Step 2: You add data with keys
K1,K2,K3, etc. Each key is hashed to a location on the ring and stored on the first node it meets clockwise.Step 3: Now, you add a new node, Node E. With consistent hashing, only the keys between Node E and the next node clockwise need to be reassigned. This ensures minimal data movement, keeping the system stable and quick.
Real-World Scenario: Using Consistent Hashing in a Shopping Website Cache
Imagine you're building a cache for a shopping site like Amazon. Here's how consistent hashing would benefit your site:
Scaling During Sales: During big sales, you need to add more servers to handle extra users. With consistent hashing, you can add nodes without needing to reshuffle all cached data, allowing seamless scaling and reducing cache misses.
Handling Server Failures: If a server fails, only the data on the failed server is reassigned to its neighbor, keeping the rest of your cache unaffected. This ensures that customers still experience fast load times.
Optimizing for Hot Keys: You can use virtual nodes to add more capacity to heavily loaded servers, ensuring that popular items (like sale items) don’t overload just one server.
Advantages and Disadvantages
Advantages:
Minimal Data Movement: Only a small subset of data changes when nodes are added or removed.
Scalability: Easy to scale up or down based on demand.
Fault Tolerance: Data remains accessible even if a node goes down, especially with replication.
Disadvantages:
Implementation Complexity: Setting up virtual nodes, replication, and monitoring can add complexity.
Potential Hotspots: Imbalances can still occur without careful planning, especially for high-demand data points.
Final Thoughts
Consistent hashing has become essential for scalable, reliable distributed systems, from data caching and load balancing to distributed databases and beyond. By mapping nodes and data to a circular hash ring, it minimizes disruptions during scaling and makes load distribution more predictable.
Implementing consistent hashing with best practices like virtual nodes and fault tolerance can give your distributed system the robustness it needs to handle real-world demands. So next time you’re working on a scalable application, consider consistent hashing—it could be the key to your architecture’s success.